Les concepts d’Overfitting et Underfitting en Machine Learning
Le sur-ajustement (overfitting) et le sous-ajustement (underfitting) sont deux des pires problèmes dans le Machine Learning. De la régression linéaire la plus simple au réseau neuronal le plus profond, rien n’est épargné. Cet article explique comment éviter ces problèmes et améliorer considérablement la performance de vos modèles de Machine Learning.
Quelques bases…
Tout d’abord, examinons quelques bases. Le machine learning est la capacité des ordinateurs à apprendre sans être explicitement programmés. Bien sûr, on doit d’abord créer un algorithme de machine learning. Cela signifie qu’on doit construire un modèle sur lequel se basera l’ordinateur. On fournit le modèle avec des entrées (connue comme entités) et les sorties associées (connus comme étiquettes), pour qu’il connaisse la relation entre les deux. Eventuellement, on veut que le modèle soit capable de fournir lui-même les sorties quand on lui donne de nouvelles entrées que l’ordinateur n’a pas encore rencontrées, par exemple, un modèle qui prédit la hauteur d’une plante en fonction de la teneur en eau du sol.
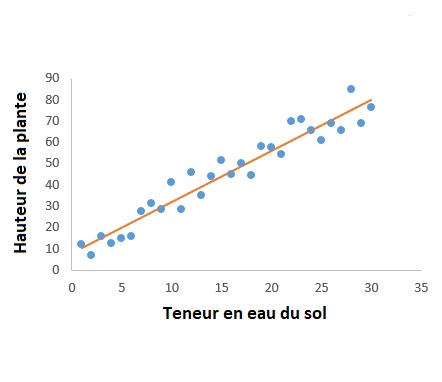
Pour que cela soit possible, le modèle doit être entraîné. Pendant le processus d’entraînement, le modèle apprend à mapper les entités aux étiquettes. Ensuite, on teste le modèle en ne lui fournissant que des entités. Les prédictionsqu’il fait déterminerontsaprécision.
Dans l’exemple précédent, la tendance entre la hauteur de la plante et la teneur en eau du sol est linéaire, mais les différentes hauteurs ne se situent pas toutes sur la même ligne: cela est parce qu’il y a des facteurs autre que la teneur en eau du sol qui affectent la hauteur de la plante. C’est ce qui cause le bruit dans le graphique, ç.a.d. la variance parmi les étiquettes. Le bruit est en fait important pour le bon entraînement du modèle parce que, dans le monde réel, les données ne correspondent pas toujours à une tendance exacte, parce que « ceteris non paribus ». Cependant, on veut que le modèle apprenne la tendance (connue comme fonction) de manière aussi réaliste que possible sans être distrait par le bruit, qui autrement nuirait à sa performance.
L’ajustement et la généralisation
La discussion ci-dessus nous amène aux concepts d’ajustement (fitting) et de généralisation. L’ajustement correspond à la mesure dans laquelle le modèle se rapproche de la fonction. Cependant, ce n’est pas la seule chose qui compte. La généralisation est également importante. Il s’agit de la mesure dans laquelle le modèle s’applique aux nouvelles données qu’il n’a pas rencontrées pendant l’entraînement. Le but d’un modèle de machine learning est d’avoir un bon ajustement aussi bien qu’une bonne généralisation. Cela permettra au modèle de faire des prédictions sur des données qu’il n’a pas précédemment rencontrées.
Les problèmes de sur-ajustement et de sous-ajustement
Le sur-ajustement se produit quand le modèle se rapproche tellement de la fonction qu’il prête trop attention au bruit. Le modèle apprend la relation entre les entités et les étiquettes en tellement de détails et capte le bruit. Cela peut causer des fluctuations aléatoires dans la fonction. Conséquemment, lorsque le modèle reçoit de nouvelles données, il ne pourra pas généraliser les prédictions. Cela est dû au fait qu’il dépend trop des données et tient compte de ces fluctuations, qui ne s’appliquent pas nécessairement aux nouvelles données.
La plupart du temps, le sur-ajustement se produit dans les méthodes non-paramétriques et non-linéaires du machine learning. Cela s’explique par le fait que ces méthodes ont plus de flexibilité sur la manière dont elles construisent des modèles en raison des formes qu’elles peuvent prendre pour la fonction. Conséquemment, elles peuvent construire dans modèles qui sont irréalistes.
Le diagramme suivant illustre le sur-ajustement. Alors que la ligne noire représente le modèle généralisé, la ligne verte représente un modèle sur-ajusté. Il tient compte de chaque point et amène le modèle à s’adapter au bruit, qu’on ne veut pas.
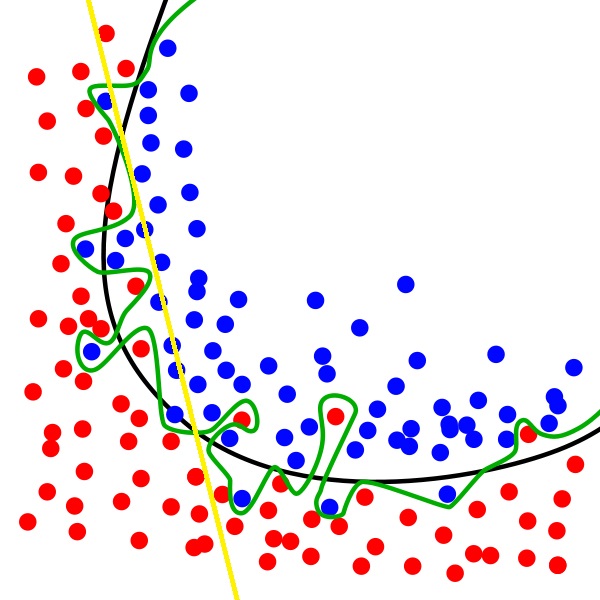
Le sur-ajustement fait que les modèles ont une forte variance et un faible biais. Cela signifie que les sorties varieront considérablement en fonction des données d’entraînement parce que le modèle en dépend beaucoup. Au lieu d’apprendre la relation, le modèle mémorisera les données. Cela va à l’encontre du but de « learning » (apprentissage) dans le « machinelearning ». Donc, bien que le modèle fonctionne très bien avec les données d’entraînement, il aura une faible généralisation aux autres données.
Le sous-ajustement est le contraire du sur-ajustement. C’est lorsque le modèle ne se rapproche pas assez de la fonction et est donc incapable de saisir la tendance sous-jacente des données. Il ignore une grande partie des entités et conséquemment produit des étiquettes incorrectes. Semblable au sur-ajustement, lorsque le modèle reçoit de nouvelles données, il ne pourra pas généraliser les prédictions. La raison ici est qu’il ne s’ajuste pas assez aux données.
Le sous-ajustement se produit d’habitude lorsqu’il n’y a pas assez de données ou lorsqu’on essaie de construire un modèle linéaire avec des données non-linéaires. Conséquemment, le modèle est trop simple pour faire des prédictions correctes.
Dans le diagramme précédent, la ligne jaune représente le sous-ajustement. Bien qu’il ne tienne pas compte de chaque point et qu’il ignore le bruit, il ignore aussi une grande partie des données.
Le sous-ajustement fait que les modèles ont un fort biais et une faible variance. Cela signifie qu’une grande partie des données est ignorée, bien que les sorties soient généralement cohérentes. Contrairement au sur-ajustement qui mémorise au lieu d’apprendre, le sous-ajustement est comme l’étudiant paresseux qui apprend juste un peu et en a fini avec. Donc, le modèle fonctionne mal avec les données d’entraînement tout comme il généralise mal les autres données.
Le bon ajustement
Un bon ajustement pour le machinelearning est un modèle équilibré entre le sur-ajustement et le sous-ajustement. Il y a juste assez de variance et juste assez de biais. Comme indiqué précédemment, dans une telle situation, le modèle apprend la tendance de la manière la plus réaliste possible sans être distrait par le bruit.
Normalement, un modèle s’améliore avec le temps à mesure qu’il s’entraîne de plus en plus, avec de nouveaux jeux de données et des corrections appropriées lors des évaluations. Cependant, on doit savoir quand s’arrêter afin d’éviter que le modèle soit submergé de données, ce qui conduirait autrement au sur-ajustement.
Comment éviter le sur-ajustement et le sous-ajustement?
Le sur-ajustement se produit plus souvent que le sous-ajustement. Une des solutions les plus populaires au sur-ajustement est la validation croisée. On divise les données d’entraînement en différents sous-ensembles et on les utilise pour entraîner et tester le modèle plusieurs fois. Ensuite, on calcule une estimation de la performance sur les différents entraînements.
En ce qui concerne le sous-ajustement, on doit toujours s’assurer qu’on a assez de données et que le type du modèle convient au type des données.
Cette partie nécessite un nouvel article détaillé. On en parlera très bientôt dans un autre article de blog.
Conclusion
Le sur-ajustement et le sous-ajustement sont nuisibles à la performance d’un modèle de machine learning. Heureusement, ces problèmes peuvent être évités avec des solutions très pratiques.
Quels défis rencontrez-vous lors de l’entraînement de votre modèle de machine learning?