La popularité du machine learning n’est plus à prouver et en tant que data scientist en herbe, vous ne vouliez pas passer à côté. Vous avez suivi quelques MOOCs et en suivant de près l’actualité du domaine, vous avez réussi à dénicher un bon jeu de données pour commencer un projet personnel. Mais les choses ne se sont malheureusement pas passées comme prévues, puisque votre modèle de séries temporelles n’était pas aussi performant qu’escompté.
Pas de panique ! Ezako est là pour vous aider. Voici 5 étapes pour vous guider dans la construction de votre modèle de machine learning. N’hésitez pas à l’utiliser comme anti-sèche pour être sûr de ne rien avoir oublié
1. Préparation de vos données
La préparation de données avant la modélisation est probablement l’étape la plus cruciale dans la création de votre modèle de séries temporelles. Pas d'inquiétude, ce n’est pas toujours aussi difficile qu’on imagine.
Sélection des données
Commencez par collecter et sélectionner vos données. Il vous faut certainement une quantité de données brutes assez importante pour votre projet, mais ne gardez que ce qui est réellement pertinent. C’est fondamental pour la réussite de votre projet, puisque se débarrasser du bruit dans les données augmente la performance de votre modèle et réduit les problèmes liés au stockage de données inutiles.
Formatage des données
Les données brutes peuvent avoir de nombreux formats différents, sans que ce soit ceux dont a besoin. Commence alors la phase de (re)formatage : il s’agit de convertir vos données brutes dans un format de stockage qui convient. Des formats aussi simples que du texte ou des fichiers csv peuvent convenir, mais avez-vous pensé à des bases de données plus complexes (comme InfluxDB, QuasarDB ou KDb+ par exemple) avec des tables, des clés et des relations qui peuvent peut-être mieux convenir au fur et à mesure que votre projet prend de l’ampleur ?
Nettoyage des données
La dernière étape de préparation consiste à nettoyer les données. En effet, il peut y avoir des valeurs manquantes ou des valeurs aberrantes qu’il faut traiter. Plusieurs choix s’offrent à vous : faut-il éliminer les valeurs aberrantes ? Faut-il supprimer toutes les entrées avec ces observations ? Faut-il remplacer ces valeurs par de nouvelles ?
Le choix ne doit pas se faire à la légère, puisque ces observations peuvent en réalité être des points d’intérêt à ne pas négliger. La détection d’anomalie est un champ à part entière du machine learning; c’est pourquoi le nettoyage de données n’est pas immédiat et requiert une attention particulière.
2. Visualisez vos données
À ce stade, un très bon réflexe est d’explorer les données qu’on vient de préparer en les visualisant. Cela paraît évident, mais de nombreux data scientists foncent tête baissée dans la modélisation sans connaître les tendances et les motifs évidents dans leur données. Par exemple, un simple graphe permet tout de suite de détecter visuellement des phénomènes de stationnarité. Des outils statistiques, y compris les plus basiques, permettent de mieux saisir la distribution des données. Même si le nombre de dimensions est élevé, visualiser les données reste possible à travers des techniques comme les histogrammes, les matrices de corrélation, les projections de données ou encore via une représentation des coordonnées parallèles.
Cela ne prend que quelques instants à mettre en place, mais visualiser ses données permet d’éviter beaucoup d’incompréhensions lorsque notre modèle n’a pas les résultats attendus.
3. Modélisation
Avant toute chose, il faut définir un objectif. Étant donné qu’il existe beaucoup de modèles de machine learning différents, votre choix dépendra surtout de vos données et de votre objectif. Votre analyse ne sera pas la même selon que vous voulez prédire le cours de la bourse ou que vous cherchez à détecter une anomalie dans une voiture autonome.
Une fois l’objectif défini, il faut choisir la bonne approche. Si vous avez seulement besoin d’identifier des similarités ou des motifs récurrents dans vos données pour des fins de prédiction, adopter un modèle non-supervisé. Si vos données sont labellisées et que vous traitez des problèmes de classification ou de régression où l’issue n’est pas connue d’avance, optez plutôt pour des modèles supervisés. Il existe beaucoup de ressources en ligne pour vous aider à choisir le bon algorithme pour votre modèle, à tel point qu’on peut se sentir perdu. Il n’y a pas de mal à choisir un algorithme qui ne soit pas le meilleur, tant qu’il constitue un bon point de départ pour la suite.
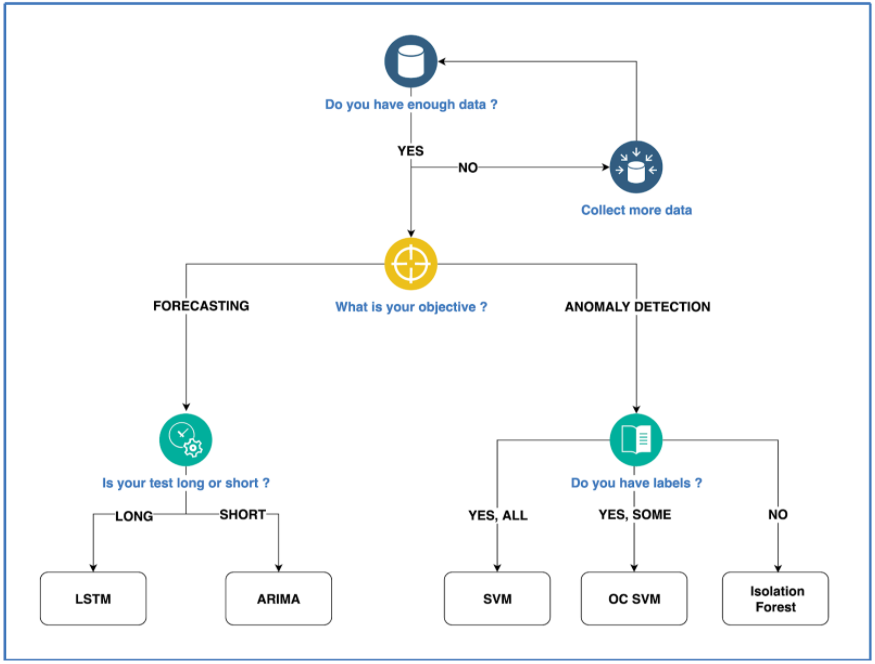
N’ayez pas peur de choisir la simplicité si vous n’êtes pas sûr de l’algorithme à choisir. Avoir de nombreux hyperparamètres à définir et optimiser peut rendre la tâche plus compliquée qu’elle n’a besoin de l’être. Par exemple, si vous cherchez à faire de la détection d’anomalie, une simple isolation forest avec une faible contamination est un bon début avant de s’essayer à des algorithmes de deep learning.
4. Évaluation de la performance
Évaluer les performances de son modèle permet de progressivement affiner la qualité des résultats obtenus. Il est probable qu’il faille évaluer plusieurs fois son modèle, sous différents angles. Il faut alors construire un cadre de performance dans lequel vous définissez quelles mesures vous adoptez pour évaluer, entre autres, la performance ou la sélection des données de test et d’entraînement. Encore une fois, le choix vous revient selon ce que vous cherchez à accomplir : cherchez vous par exemple à évaluer la précision du modèle ou le taux d’erreurs quadratiques moyennes?
Une fois ce cadre défini, faites de la validation croisée. L’idée est de diviser vos données en plusieurs échantillons et d’entraîner votre modèle sur tous les échantillons, sauf un qui servira pour tester le modèle. Ce processus est répété jusqu’à ce que tous les échantillons aient été testés et que vous ayez réalisé toutes les mesures définies dans le cadre de performance. La validation croisée est une méthode efficace pour tester toutes les données sans rencontrer de problèmes liés au surapprentissage.
Même si évaluer votre modèle est important, prenez soin de chercher à optimiser tout le processus de machine learning afin de tirer les meilleurs résultats possibles.
5. L’export en production
Tout ce qu’il reste à faire est d’exporter votre travail. Cela peut sous-entendre bien plus que simplement exporter un algorithme (comme ça peut être le cas pour un petit projet personnel). Pour des projets plus importants, il est possible que vous deviez réécrire votre travail dans le langage de production. Des serveurs comme AWS EC2 sont de très bons moyens d'accéder aux infrastructures dont vous avez besoin, mais des services dédiées au machine learning comme Microsoft Azure peuvent vous aider à vous lancer plus rapidement au détriment de certaines fonctionnalités. Une alternative plus élégante est de conteneurisée votre solution (grâce à Docker, par exemple) puisque vous n’aurez plus à subir des limitation système ou physique. Enfin, Upalgo est un moyen de créer et de déployer vos algorithmes en production en toute simplicité.
Conclusion
Construire un modèle de séries temporelles n’est pas ce qu’il y a de plus simple, mais continuez d’améliorer votre modèle en implémentant de nouvelles méthodes pour améliorer vos compétences.
Pour plus de détails, n’hésitez pas à jeter un œil au livre blanc d’Ezako sur le sujet.