Overfitting and Underfitting Concepts in Machine Learning
Overfitting and underfitting are two of the worst plague in Machine Learning. From the simplest linear regression to the deepest neuronal network, no one is spared. This article will explain how to keep you safe from these, and greatly improve the performance of your Machine Learning models.
Some basics…
First of all, let us go over some basics. Machine learning is the ability of computers to learn without being explicitly programmed. Of course, we still need to first create a machine learning algorithm. This means that we need to build a model upon which the computer will base itself. We provide the model with inputs (known as features) and the related outputs (known as labels), so that it knows the relationship between them. Eventually, we want the model to be able to provide output by itself when we give it new inputs that the computer has not yet encountered, for example, a model that predicts plant height based on soil water content.
 For this to be possible, the model needs to be trained. During the training process, the model learns how to map the features to the labels. Then, we test the model by providing it only with features. The predictions that it makes will determine its accuracy.
For this to be possible, the model needs to be trained. During the training process, the model learns how to map the features to the labels. Then, we test the model by providing it only with features. The predictions that it makes will determine its accuracy.
In the previous example, the trend between plant height and soil water content is linear, but the different heights do not all lie on the same line: this is because there are factors other than soil water content that affect plant height. This is what causes the noise in the graph, i.e. the variability in the labels. Having noise is actually important for the successful training of the model because, in the real world, data does not always fit an exact trend, because “ceteris non paribus”. However, we want the model to learn the trend (known as function) as realistically as possible without being distracted by the noise, which would otherwise negatively affect its performance.
Fitting and generalisation
The discussion above brings us to the concepts of fitting and of generalisation. Fitting is how well the model approximates to the function. However, this is not the only thing that matters. Generalisation is also important. It concerns how well the model applies to new data that it has not encountered during training. The goal of a machine learning model is to have a good fit as well as a good generalisation. This is so that the model can make predictions on data that it has not previously encountered.
The problems of overfitting and underfitting
Overfitting is when the model approximates to the function so much that it pays too much attention to the noise. The model learns the relationship between the features and the labels in so many details and picks up the noise. This can cause random fluctuations in the function. Consequently, when the model receives new data, it will not be able to generalise the predictions. This is because it relies too much on the data and takes into consideration those fluctuations, which do not necessarily apply to the new data.
Most of the time, overfitting occurs in non-parametric and non-linear machine learning methods. This is explained by the fact that those methods have more flexibility over how they build models because of the forms that they can take for the function. As a result, they can build models that are unrealistic.
The following diagram illustrates overfitting. While the black line represents the generalised model, the green line represents an overfitted model. It accounts for every single point and causes the model to fit the noise, which we do not want.
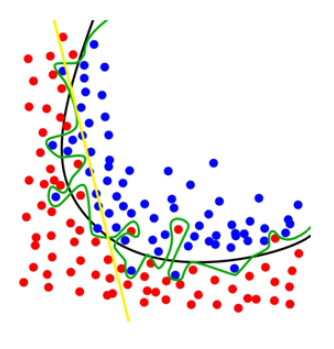
Overfitting causes models to have a high variance and a low bias. This means that the output will vary greatly based on the training data because the model depends a lot on it. Instead of learning the relationship, the model will memorise the data. This defeats the whole purpose of “learning” in “machine learning”! So, although the model performs great with training data, it will have a poor generalisation to other data.
Underfitting is the opposite of overfitting. It is when the model does not enough approximate to the function and is thus unable to capture the underlying trend of the data. It ignores many features and consequently produces incorrect labels. Similar to overfitting, when the model receives new data, it will not be able to generalise the predictions. The reason here is that it does not fit the data well enough.
Underfitting usually happens when there is not enough data or when we try to build a linear model with non-linear data. As a result, the model is too simple to make any correct predictions.
In the previous diagram, the yellow line represents underfitting. Although it does not account for every single point and ignores the noise, it also ignores much of the data.
Underfitting causes models to have a high bias and a low variance. This means that much of the data is ignored, although the output will generally be consistent. In contrast to overfitting which memorises instead of learns, underfitting is like the lazy student who learns just a little and is done with it. So, the model performs poorly on training data as much as it has poor generalisation on other data.
The good fit
A good fit for machine learning is a balanced model between overfitting and underfitting. There is just enough variance and just enough bias. As previously stated, in such a situation, the model learns the trend as realistically as possible without being distracted by the noise.
Usually, a model improves over time as it trains more and more, with new datasets and appropriate corrections during evaluations. However, we should know when to stop so as to avoid the model from being overwhelmed with data, which would otherwise lead to overfitting.
How to avoid overfitting and underfitting?
Overfitting occurs more often than underfitting. One of the most popular solutions to overfitting is cross-validation. We split the training data into different subsets and we use them to train and test the model several times. Then, we calculate an estimate of the performance over the various training.
As for underfitting, we should always make sure that we have enough data and that the type of the model is suitable for the type of the data.
This part deserves a new detailed article. And we will be talking about it very soon in a new blog post.
Conclusion
Overfitting and underfitting are detrimental to the performance of a machine learning model. Fortunately, these problems can be avoided with very practical solutions.
What challenges do you encounter when training your machine learning model?